Frequently Asked Questions
About the Project
What is just-dna-lite?
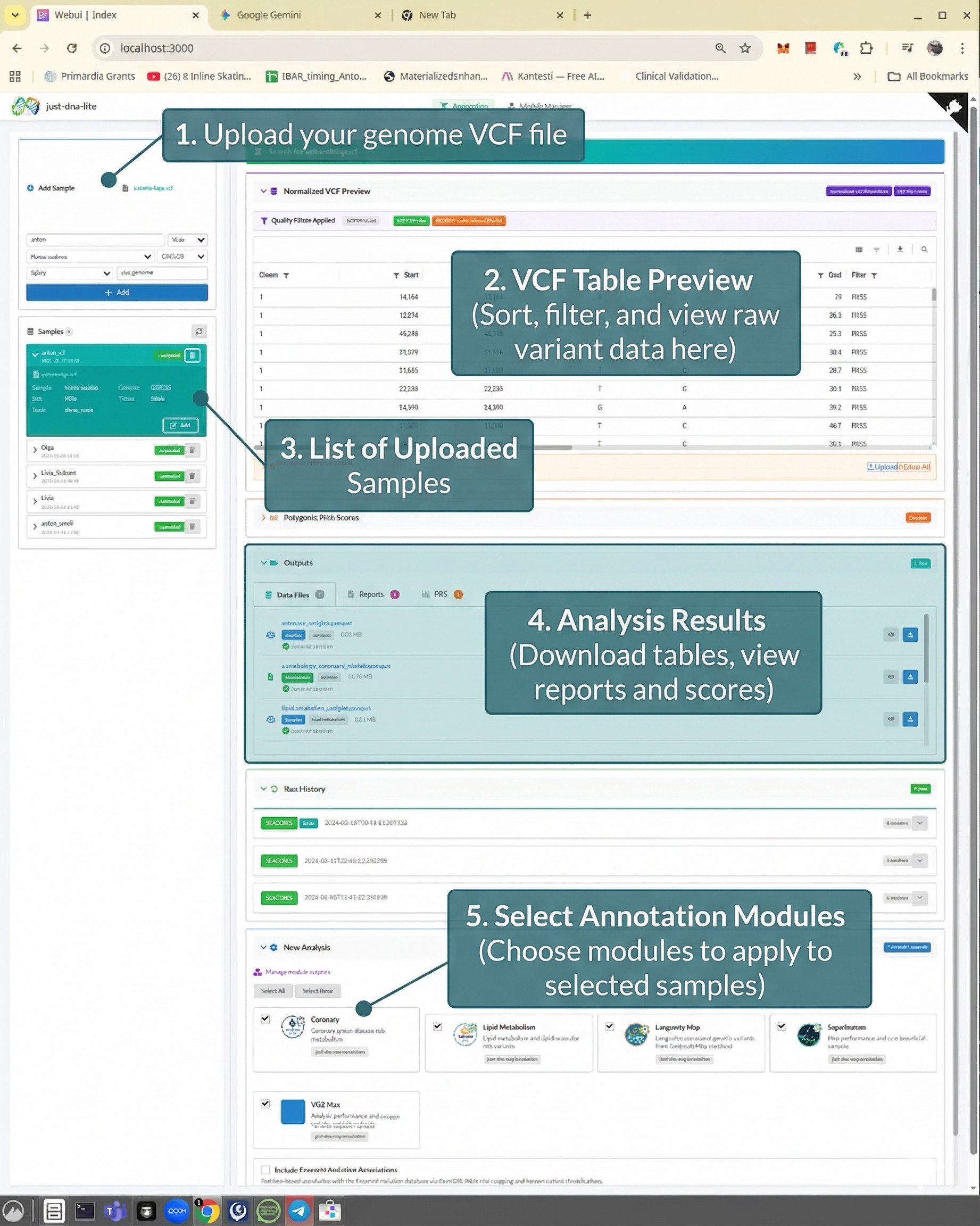
just-dna-lite is an open-source platform for personal genome annotation. You upload a genome file (VCF), pick what you want to know, and get results in minutes. It runs entirely on your machine — nothing leaves your computer. The source code is on GitHub under the AGPL v3 license.
Who is behind this project?
The project was started by Anton Kulaga and Nikolay Usanov, who wanted to understand their own genomes and got tired of being the bioinformaticians without shoes — building tools for everyone else but having nothing good for personal use. Other contributors joined along the way, including geneticist Olga Borysova who built the expert-curated annotation modules. The full list is on the GitHub contributors page.
Where is the source code?
Everything is on the dna-seq GitHub organization:
- just-dna-lite — the main platform
- just-prs — polygenic risk score library
- prepare-annotations — upstream data preparation pipelines
Annotation modules and reference datasets are published to the just-dna-seq organization on HuggingFace.
How do I install it?
See the Quick start section in the README. It runs on Windows, macOS, and Linux — installers are available for Windows and macOS, and on Linux you can run from source in four commands. No Docker required (though container deployment is also supported).
What file format does it accept?
VCF (Variant Call Format) files with .vcf or .vcf.gz extensions from whole genome (WGS) or whole exome (WES) sequencing. Only GRCh38-aligned VCFs are fully supported. GRCh37/hg19 and T2T support are planned.
Does it work with 23andMe / AncestryDNA / MyHeritage data?
Not yet. Those services use microarray chips that read a few hundred thousand pre-selected positions. just-dna-lite needs a file from whole genome or whole exome sequencing, which covers millions of positions. Microarray support is on the roadmap.
Where can I get my genome sequenced?
Several commercial providers offer whole genome sequencing. As of 2026, options include DNA Complete (formerly Nebula Genomics), Dante Labs, and Sequencing.com. Make sure your provider allows you to download the raw .vcf or .vcf.gz file.
If you live in Romania, the ROGEN (Romanian Genomics) project is a national initiative sequencing 5,000 individuals — you might be able to participate and get your genome sequenced.
(We are not affiliated with any of these companies or services.)
I don't have a genome file. Can I still try the tool?
Yes. Some of our authors have voluntarily open-sourced their genomes under permissive licenses:
- Anton Kulaga (CC-Zero):
https://zenodo.org/records/18370498 - Livia Zaharia (CC-BY-4.0):
https://zenodo.org/records/19487816
Paste these URLs into the "Import from Zenodo" field in the app, or download the VCF and upload it manually. You can also find other public genomes on platforms like Open Humans.
Understanding the Science
What do the annotation modules do?
Each module is a curated database of genetic variants with effect weights from published research. When you run an annotation, the tool joins your VCF against the module's variant table and shows which of your variants match, along with context from the source studies — whether a variant is considered protective or risky, the gene involved, and a brief conclusion from the literature.
What annotation modules are included?
The tool ships with five expert-curated modules: Longevity Map (variant-trait associations from the LongevityMap database), Coronary Artery Disease, Lipid Metabolism, VO2 Max, and Athletic Performance (Superhuman). These were created with the expert curation of geneticist Olga Borysova. More modules can be added by hand or generated with the AI Module Creator.
What is Ensembl annotation?
When enabled, the pipeline joins your variants against the Ensembl Variation database (~1.1 billion rows). This provides clinical significance labels, consequence types, and cross-references for each variant. The Ensembl cache is about 14 GB and is downloaded on first use. You can pre-download it with uv run pipelines ensembl-setup.
What is a polygenic risk score (PRS)?
A PRS is a weighted sum of genetic variants from genome-wide association studies. The result is a number that tells you where you sit in a reference population's distribution. It is a rank, not a probability of disease. The model is linear; real biology is not — gene-gene interactions, gene-environment interactions, and developmental factors are not captured.
Over 5,000 PRS from the PGS Catalog are available. Scores are computed via just-prs with Pearson r = 0.9999 concordance against the established PLINK2 reference tool.
What does "heritability" actually mean?
When scientists say a trait is "60% heritable," most people read "60% determined by genes." That is not what it means. Heritability is a population-level statistic — it measures how much of the variation between people in a specific study is associated with genetic differences. It changes depending on the environment. Height is about 80% heritable in well-nourished populations; that number drops in populations with childhood malnutrition. The genes didn't change. The environment did.
A high heritability does not mean "your genes doom you." It means the number depends on the population and environment where the study was done.
Are GWAS findings the same as proven biological mechanisms?
No. Most variants in annotation modules are statistical associations found through genome-wide association studies. Many GWAS hits are "tagging" variants — correlated with a nearby causal variant but not causal themselves. Effect sizes also consistently shrink in replication studies.
How accurate are PRS for non-European ancestry?
Less accurate, sometimes substantially. Most PGS Catalog scoring files were derived from predominantly European cohorts. The statistical associations depend on allele frequencies and linkage disequilibrium patterns that vary across populations. just-prs provides percentile ranking against five 1000 Genomes superpopulations (African, American, East Asian, European, South Asian), but the underlying scores were still mostly built from European data.
I got a high PRS for a disease or found a "pathogenic" variant. What should I do?
Don't panic. This is research-grade information, and context matters enormously.
Studies of healthy populations show that the average person carries dozens to hundreds of variants flagged as "pathogenic" in research databases. Many of these entries are false alarms, reclassified over time, or have very low penetrance (meaning they only cause disease in a tiny fraction of carriers). For common chronic diseases, lifestyle factors — smoking, activity, diet, sleep — have larger effect sizes than any common genetic variant.
We built this tool for exploration and self-education. We know people will look at their health-related results, and that is the whole point — you have the right to look at your own genome. But you need to know what you are looking at: this is research-grade evidence, not a clinical test. If something concerns you, especially if it aligns with your family history, the right next step is to talk to a doctor or genetic counselor and get the finding validated with a clinical-grade test (like Sanger sequencing from a certified lab). The danger is not in looking — it is in acting on research-grade results without proper validation.
For a deeper dive, see Understanding What Your Genome Can and Cannot Tell You.
What findings are genuinely high-confidence?
A small number of genetic findings are near-deterministic and clinically actionable:
- Monogenic diseases — one or two broken copies of a gene cause a specific disease with high penetrance. Examples: Huntington's disease, familial hypercholesterolemia (LDLR, APOB, PCSK9), hereditary BRCA1/2 breast/ovarian cancer, Lynch syndrome.
- Pharmacogenomics — CYP2C19 loss-of-function affects clopidogrel activation; HLA-B*57:01 predicts abacavir hypersensitivity. These have direct clinical implications.
- High-penetrance rare variants — e.g., APOE e4/e4 for Alzheimer's, TTR for hereditary amyloidosis.
Everything outside this short list — the vast majority of what a genomic tool surfaces — is associative, probabilistic, and heavily context-dependent.
AI Module Creator
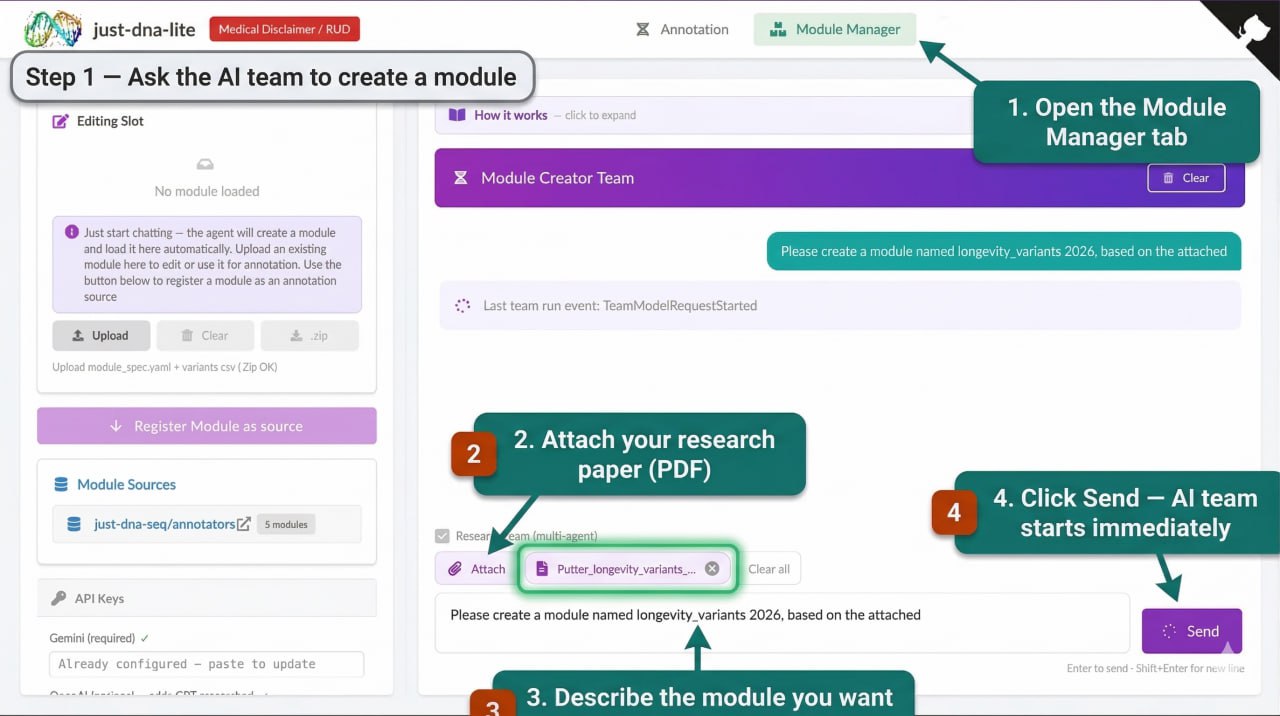
What is the AI Module Creator?
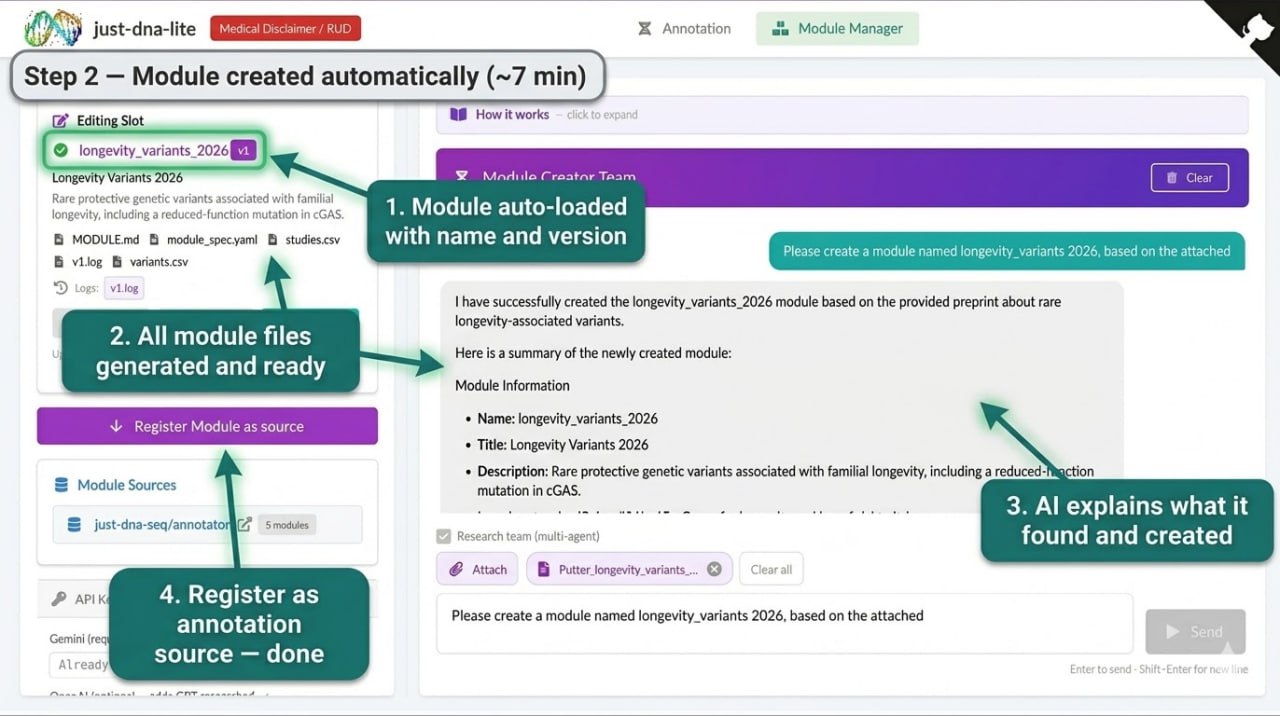
An agentic pipeline that turns a research paper (PDF, CSV, or text description) into a validated annotation module. You upload a paper, describe what you want, and the AI reads it, queries biomedical databases (EuropePMC, Open Targets, BioRxiv), extracts variants, and produces a ready-to-use module.
How reliable are AI-generated modules?
They are automated first drafts, not expert-curated databases. They will contain mistakes. The research team mode mitigates this by running multiple language models independently and only keeping variants confirmed by at least two, but errors still happen. Every AI-generated module is labeled as such (the curator field says "ai-generated"). Review the output before relying on it.
What is the difference between simple mode and research team mode?
- Simple mode: One AI agent handles everything. Faster (~2 minutes), good for a single well-defined paper.
- Research team mode: A Principal Investigator dispatches up to three Researcher agents (different language models) in parallel, then a Reviewer fact-checks via web search. Takes ~7–8 minutes, but cross-model agreement reduces hallucination.
Do I need API keys for the AI Module Creator?
You need at least one LLM API key. Any powerful model works — including local ones via an OpenAI-compatible API (e.g. Ollama, vLLM). We have mostly tested with Gemini because free API keys are easy to get at Google AI Studio (short video on how), but GPT, Claude, and other models work too — some better, some worse, since prompts behave differently across models. In research team mode, having keys for multiple providers (Gemini + OpenAI + Anthropic) lets the system run different models as independent researchers in parallel, which improves quality through cross-model agreement.
Everything else in just-dna-lite (annotation, PRS, self-exploration) works without any API keys.
Can I create a module by hand without AI?
Yes. A module is just a directory with two files: module_spec.yaml (metadata) and variants.csv (variant table with rsID, genotype, weight, state, conclusion, gene). No programming required. See the README for the format.
Privacy and Data
Does my data leave my computer?
No. All computation happens locally. The VCF file is never transmitted to any external server. Annotation databases are cached locally after a one-time download. Results are stored on your local filesystem.
What about the annotation databases?
They are downloaded once from HuggingFace, Zenodo, or other sources, then cached locally (~/.cache/just-dna-pipelines/). After that, everything runs offline. The downloads contain reference data, not your personal data.
Can my employer, insurer, or government access my results?
Not through this tool. Everything runs on your machine and nothing is uploaded, so there is no server for anyone to subpoena or hack. Your genome data stays in the folders you choose, protected by your operating system's file permissions. If physical access to your computer is a concern, use disk encryption and strong passwords.
Why can't I upload my genome on the public demo?
Processing personal genomic data on a shared server triggers GDPR, HIPAA, and other data protection regulations requiring extensive compliance infrastructure. The demo only works with genomes already published on Zenodo under permissive licenses — if you have published yours there, you can import it via the Zenodo URL. We currently support only Zenodo because it is a reputable repository with clear, machine-verifiable open licenses; support for other trusted repositories is planned. For private genomes, install just-dna-lite locally — see the Quick start.
Legal and Regulatory
Is this a medical device?
No. just-dna-lite is a bioinformatics research tool for academic studies, citizen science, and educational self-exploration. It is not approved, cleared, or certified by any regulatory body (FDA, EMA, or equivalent) and is not intended for clinical diagnostic use.
What is the difference between research-grade and clinical-grade evidence?
For a genetic finding to be clinical-grade, it needs to be demonstrated — in well-designed prospective studies — that knowing the result changes patient outcomes. It needs to work across diverse populations, be reproducible under routine laboratory conditions, and the benefits must outweigh the harms.
Very little of genomics has cleared that bar. The exceptions include BRCA1/2 for breast/ovarian cancer, pharmacogenomic variants like CYP2C19 and HLA-B*57:01, and monogenic conditions like Huntington's. Most complex trait polygenic scores are science-grade — they tell you something real about population distributions but do not predict individual outcomes.
Our tool surfaces research-grade evidence. It is genuinely informative if you understand what the numbers mean, but it is not a substitute for clinical testing when clinical testing is warranted.
Is this GDPR-compliant?
The architecture is GDPR-friendly by design. All data processing happens locally, so you are the data controller. There is no third-party data processing, no cloud upload, and no data sharing. The open-source code allows anyone to audit every line that touches their data.
For public demos and workshops, the app has an immutable mode that blocks all user uploads and only works with genomes that their owners have already voluntarily published on Zenodo under open licenses (CC-Zero, CC-BY, etc.). These are still personal genomes, but their owners chose to make them public — the demo server does not accept anyone else's data.
What is the license?
AGPL v3. The software is provided "AS IS", without warranty of any kind. See the full LICENSE. The AGPL allows commercial use, but derivative works distributed or offered as a network service must also be released under AGPL v3 with full source code.
Technical
How fast is annotation?
About 39 seconds for a whole-genome VCF (~6.1 million variants) against the default modules, with peak RAM under 750 MB. Cold start (first run, cache initialization) takes about 203 seconds. These numbers are from a server with HDD storage — SSD and modern laptops will be faster.
What technologies does it use?
Dagster (pipeline orchestration), Polars (data processing), DuckDB (out-of-core SQL joins), polars-bio (VCF reading), Reflex (web UI, pure Python), and just-prs (PRS computation).
What output formats are available?
Primary outputs are Parquet files (Polars, Pandas, DuckDB, R, or any Arrow-compatible tool). PDF/HTML reports are generated per annotation run. VCF export produces standard VCF files with annotations in the INFO column.
How do I report a bug or request a feature?
Open an issue on GitHub. Pull requests are welcome.